

Feb 2, 2026
Why speech-to-speech is the future for AI voice agents: Unpacking the AIEWF Eval

Zach Koch
Speech-to-speech is the future of voice AI–and as shown in the newly-released AIEWF eval, Ultravox’s speech-native model can outperform both frontier speech models and text models alike.
One of the ways we regularly test the intelligence of voice AI models is with standardized benchmarks, which test the model’s ability to perform tasks like transcribing audio, solve logic puzzles, or otherwise demonstrate reasoning based on spoken prompts.
But modern voice agents need to do more than just understand speech–they need to reliably follow instructions, participate in extended multi-turn conversations, perform function calls, and reference information from a knowledge base or RAG in responses.
Kwindla Kramer and the team at Daily have taken a new approach to creating a model evaluation framework that tests the capabilities that matter for production voice agents, beyond basic speech understanding. The AIEWF eval considers many of the practical requirements not tested in traditional speech understanding benchmarks–knowledge base use, tool calling, instruction following, and performance across a multi-turn conversation.
Traditional speech understanding evals like Big Bench Audio help us understand how accurately a model understands speech. The new AIEWF eval measures how well a model can reason in speech mode and complete tasks that real-world voice agents need to do.
Taken together, these evals demonstrate why speech-to-speech architectures are poised to overtake the component model for voice AI use cases.
Big Bench Audio: Evaluating speech understanding
Big Bench Audio is a widely-used evaluation framework that tests a model’s speech understanding, logical reasoning, and ability to process complex audio inputs accurately across multiple modes, including speech-to-speech and speech-to-text output. It’s a useful framework for quantifying a model’s inference capabilities given complex audio input.
High scores indicate a model that effectively understands spoken language, which requires deep investment in architecture, training, and engineering (For the record, Ultravox v0.7 scores a 91.8 on Big Bench Audio–the highest score of any speech model available at time of writing.)
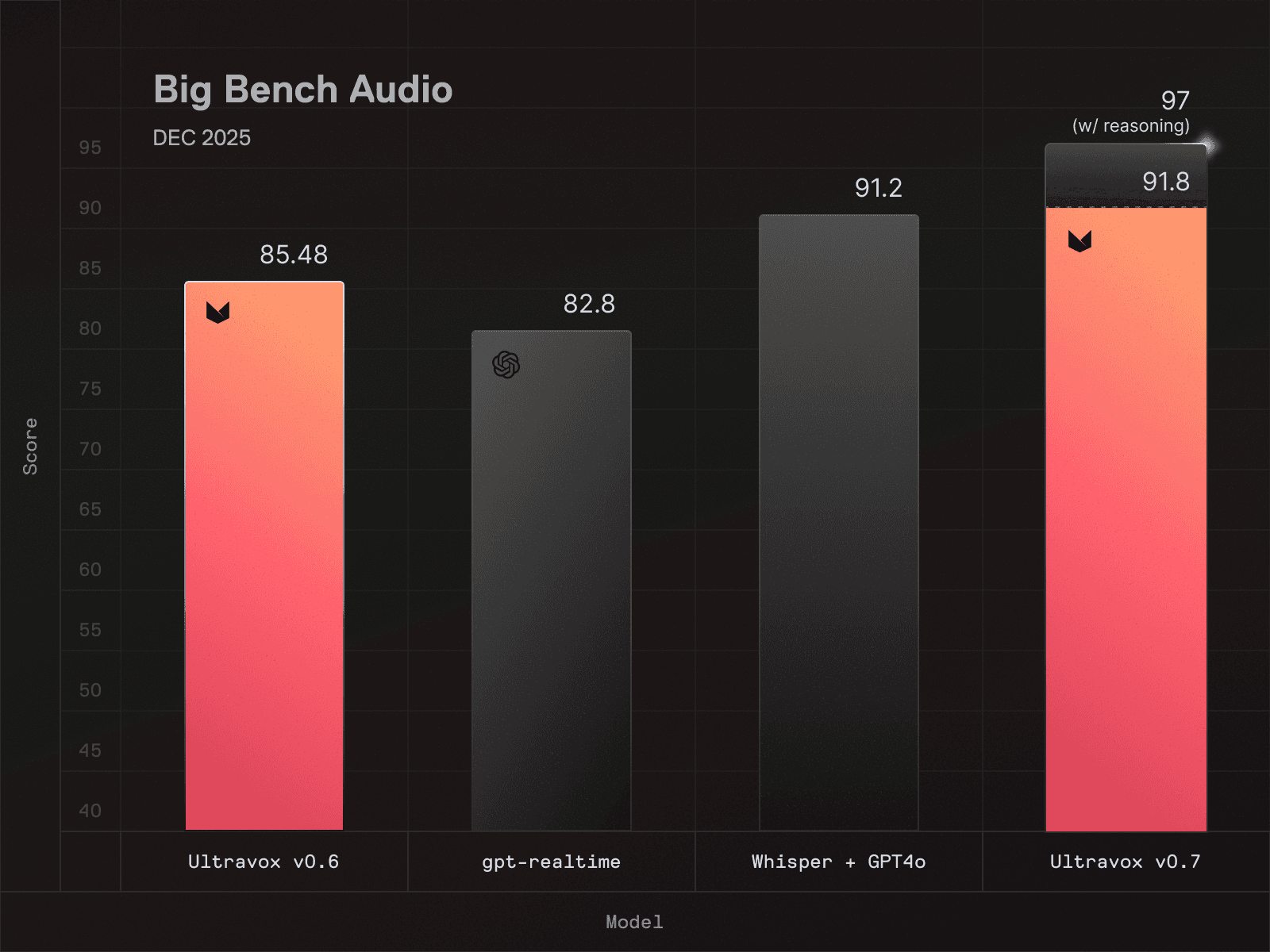
Naturally our team is excited about our achievement, but we think it’s worth being transparent about the limitations of the test itself.
Big Bench Audio measures model capability in a narrow, relatively isolated context. Here’s an example question from the Big Bench Audio eval for speech-to-speech models (transcribed from original audio sample):
Question: Osvaldo lies. Phoebe says Osvaldo lies. Candy says Phoebe tells the truth. Krista says Candy tells the truth. Delbert says Krista lies. Does Delbert tell the truth? Answer the question.
A model that can correctly answer this question (Delbert does not tell the truth) demonstrates its ability to understand spoken audio as well as its ability to reason logically about speech, both of which are relevant if you’re building a voice agent.
However, Big Bench Audio alone doesn’t tell you much about how well a model handles messy, real-time, multi-step workflows that voice agents typically face in the real world. There’s no tool calling, no complex instruction following, no background noise or interruptions. The eval is structured as a series of questions and answers that are evaluated independently, rather than as a multi-turn conversation.
In order to more accurately understand how well a speech model will perform in the real world, a test needs to measure how the model handles real-world demands. This is where things get interesting.
The AIEWF eval goes beyond speech understanding, and considers performance across:
Tool usage: Can the model correctly invoke external functions and APIs?
Knowledge base integration: Can it retrieve and synthesize information from connected data sources?
Multi-turn conversations: Can it maintain context and coherence across extended interactions?
Task completion: Can it actually accomplish what users ask it to do?
These factors reflect many of the exact workflows that developers are building when they create voice agents for customer service, scheduling, information retrieval, and countless other applications. Instead of single-turn questions and answers, this framework tests reasoning across a set of 30-turn conversations, evaluating performance in individual conversations as well as the model’s consistency from one conversation to the next.
Metric | Ultravox v0.7 | GPT Realtime | Gemini Live |
|---|---|---|---|
Overall accuracy | 97.7% | 86.7% | 86.0% |
Tool use success (out of 300) | 293 | 271 | 258 |
Instruction following (out of 300) | 294 | 260 | 261 |
Knowledge grounding (out of 300) | 298 | 300 | 293 |
Turn reliability (out of 300) | 300 | 296 | 278 |
Median response latency | 0.864s | 1.536s | 2.624s |
Max response latency | 1.888s | 4.672s | 30s |
When measured using the AIEWF multi-turn eval, Ultravox dominated the rankings for speech-to-speech models–in fact, it wasn’t even close.
While a few frontier language models were able to outperform Ultravox on these practical benchmarks, it was with a pretty significant caveat: those models are far too slow for real-time voice applications. When it comes to voice agents, low latency is table stakes, not just a nice-to-have; a 2-second pause while waiting for the model to “think” about its answer can undermine the entire conversational experience.
In short, Ultravox delivered frontier-adjacent intelligence at speeds suitable for real-time voice, delivering an overall experience that many developers might not have realized was possible.
Why speech-to-speech beats component stacks
For years, the standard approach to voice AI was building a component stack: a speech-to-text model feeds a language model, which feeds a text-to-speech model. Each component is built and optimized separately before being assembled into a pipeline.
This approach works(ish) for deterministic use cases, but it has fundamental limitations:
Latency accumulates: Every component in the pipeline adds processing time. By the time you've transcribed, reasoned, and synthesized, you've burned through your latency budget.
Errors compound: Transcription mistakes become reasoning mistakes, reasoning mistakes become response mistakes. There's no graceful recovery.
Context gets lost: The prosody, emotion, and nuance in speech disappear the moment you convert to text. The language model never sees them.
Ultravox’s speech-to-speech architecture sidesteps all of these issues, because incoming audio never goes through an initial transcription step; instead, the model performs reasoning directly on the original speech signal. The result is lower latency, fewer errors, and responses that actually reflect what the user said—not just the words, but the meaning.
The Bottom Line
Traditional benchmarks are a useful signal of a model's fundamental ability to understand speech. But if you're building voice agents, it’s important to bear in mind that traditional benchmarks only tell part of the story.
If you're building voice agents, you need a model that excels at both: strong foundational capabilities *and* practical task performance. Ultravox delivers on both fronts. Highest scores on Big Bench Audio. Top speech model on real-world voice agent tasks. Fast enough for production use.
If you're evaluating models for your next voice agent project, the choice is clear. Ultravox isn't just competitive—it's the best all-around solution available today.
Ready to build with Ultravox? Get started here or contact our team to discuss your voice agent project.