

Oct 24, 2025
Ultravox Answers: How does zero-shot voice cloning work?

Ultravox Team
Q: I followed the instructions and cloned my voice to use with my AI agent, but my voice clone doesn’t really sound like me–why isn’t it working?
We’ve encountered this type of user question often enough that we thought it was worthwhile to do a deep dive into how voice cloning works.
The short answer is that there are lots of reasons why your voice clone might sound noticeably different from your actual voice–some of these are easy to fix, while others are due to more structural nuances of how voice cloning and text-to-speech models work.
The basics of voice cloning
Humans learn language through a complex process, first by hearing and recognizing word sounds, then linking words to real-world concepts, and eventually grasping more abstract concepts like the pluperfect tense. So a four-year-old might stumble while pronouncing “apple” or “toothbrush” but will generally recognize that those words correspond to physical objects in the world around them.
Training a text-to-speech (TTS) model is wildly different. Although modern models increasingly incorporate semantic information, their understanding of individual words or sentences remains limited, unlike human comprehension. Instead, models learn the mappings from text sequences to audio waveforms via the patterns of some intermediate representation, such as spectrograms or quantized speech tokens. From there, the model can reproduce patterns that sound like human speech. A TTS model can accurately pronounce the word “toothbrush”, but without any human-like understanding of the object that word represents.
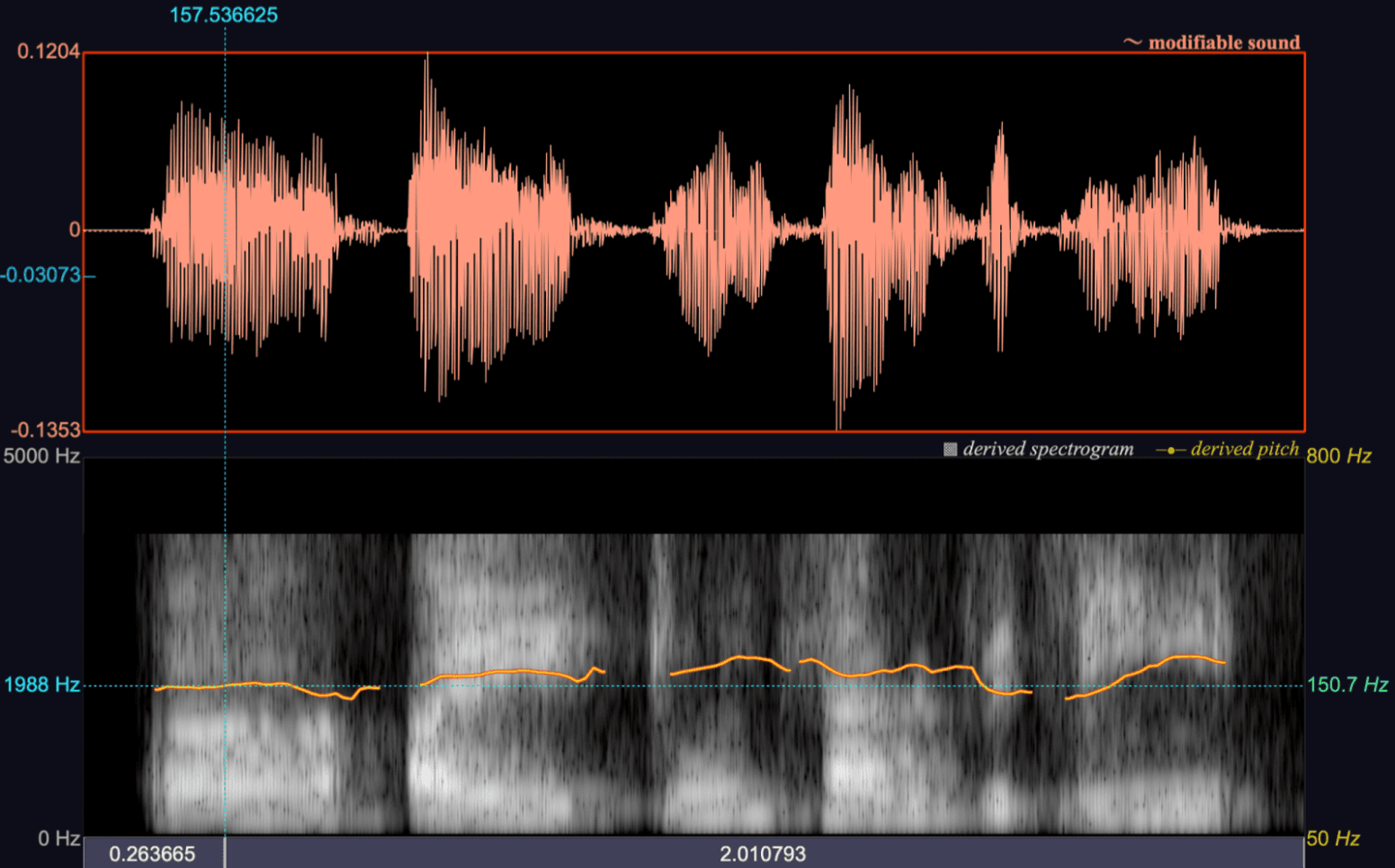
An example of a derived spectrogram, waveform, and pitch contour based on an adult male speaking voice.
Training a TTS model relies on aligned text and audio pairs: give the model a text snippet, and a corresponding audio clip of a human reading the text, and then repeat the process a few million times. Eventually, the model output for a given text sample will sound convincingly like a human reading the text aloud.
The quality and fidelity of speech generation in these models varies between languages because there is wide variety in the availability of text-audio samples for different languages and dialects. Training data for languages like English, Spanish, and Mandarin is extensive and widely available, while Farsi, Yoruba, and Khmer are considered low-resourced languages, meaning they have little in the way of paired text-audio data to train on.
Many indigenous and endangered languages have no standardized TTS datasets at all. If you speak one or more low-resourced languages, please consider contributing to Mozilla’s Common Voice project by recording, verifying, or transcribing audio samples.
Once the model has been trained on a sufficiently large and diverse dataset, it can synthesize the voice of a new human speaker from a remarkably brief sample–typically 10 to 60 seconds of audio, depending on the model’s training–without any additional fine-tuning or adaptation. This is accomplished through a process called zero-shot voice cloning.
In zero-shot voice cloning, the model analyzes a short reference clip to capture a speaker’s vocal traits–qualities like timbre, pitch, and nasality–and encodes these traits as explicit acoustic features or latent embeddings. This encoding can then guide speech generation, so the model can produce new utterances in the same voice from text alone. Some modern TTS models use the reference audio sample as a prompt prefix, but there’s no speaker-specific fine tuning or training involved.
The advantage of the zero-shot method is that it’s easily accessible–almost anyone can record a 60-second audio clip, and because there’s no fine-tuning of the generated speech beyond the initial embedding, it’s quick to do. The cloned voice won’t be a perfect match (due to the absence of fine tuning as well as for some reasons we’ll discuss below), but if what you need is a reasonably good replica of a speaker’s voice, the zero-shot method is a great option.
Limitations of the zero-shot voice cloning method
There are some aspects of human speech that even the best TTS models will struggle to replicate using the zero-shot method.
Prosody
Prosody refers to the melody and rhythm of speech; patterns like pitch, timing, and emphasis that make a speaker sound natural and expressive. While a model can often capture the basic qualities of a person’s voice, such as pitch and timbre, it’s much harder to consistently reproduce their prosody. Most speakers will share some general intonation patterns, like raising pitch to indicate a question, but individual speakers will also develop unique habits of pacing, stress, and tone that vary depending on mood and context. Depending on how the text prompt is written (for example, using punctuation marks to denote pauses or capitalization to mark emphasis) generated speech might sound like the right voice, but with the wrong delivery.
Local and complex accents
Even for languages with extensive training data available, specific local or regional accents might be under-represented. For example, French and English are both among the most high-resource languages for TTS, but Belgian French or Scottish English might appear far less frequently in training data. The challenge is even greater for regions with extensive bilingualism (like the largely German-Italian bilingual population of the South Tyrol region), as speakers will naturally mix features like phonetic and rhythmic patterns from multiple languages.
Expressiveness and emotion
For obvious reasons, a 60-second audio sample will generally not capture the full range of a speaker’s emotions (excited, sad, sarcastic, defeated) for the model to reference. While most models can reproduce emotional styles that they’ve been trained on, their ability to model a speaker’s expressiveness is limited if emotion and speaker identity are not clearly disentangled. In some cases, the cloned voice might inherit the emotional tone present in the reference sample, or simply default to an emotionally neutral delivery.
There’s one additional factor that might explain why your voice clone sounds “off”, although it’s not unique to voice cloning. When you speak, you usually hear your voice through two pathways: sound waves traveling through the air into your ears (air conduction), and vibrations traveling directly through your skull to your inner ear (bone conduction).
Solid materials like bone conduct lower frequencies more efficiently than air, so bone conduction essentially gives you an internal bass boost, making your voice sound richer and deeper when you hear yourself speak.
Audio recording, however, captures only the air-conducted sound. When you play it back, you’re missing that extra resonance from bone conduction, so your voice might sound “thinner” and higher-pitched than what you’re used to. Your brain is likely used to the blended version, but audio recordings only give you the external version that everyone else hears.
Since a voice clone embedding is also generated using only air-conducted sound from an audio sample, it might be a pretty close match to the way other people hear your speaking voice, even if it sounds a bit odd compared to the way you’re accustomed to hearing yourself.
Tips on making a better voice clone
While generated speech might not be a perfect replica of your voice, there are some steps you can take when producing an audio sample that will improve the overall quality of your voice clone:
Make sure your recording is free of background noise, especially sound from other voices, music, etc. You should be the only speaker audible on the sample.
The acoustics of the room you record in also matter–if you make your recording in a large, relatively empty space, artifacts from the background reverberation in the room can be inherited by your voice clone.
Maintain a natural speaking pace and tone throughout the entire sample recording–it might be helpful to create a brief script in advance and read it out loud.
The quality of your audio input device matters–recoring on your default laptop hardware often produces a much lower-quality sample than recording on a high-quality external microphone.